
: 爬虫编程介绍
随着互联网的快速发展,网络信息的获取和利用变得越来越重要。而爬虫技术就是获取网络信息的重要手段之一。本文将介绍爬虫编程的基础知识和实现方法,并提供一些实用技巧和注意事项。
一、爬虫基础知识
1. 什么是爬虫
爬虫(Web Spider)是指从互联网上获取数据的一种程序或脚本。通过特定的算法和模拟浏览器行为,爬虫可以自动化地访问网站,获取所需的页面信息,并进行数据分析和处理。
2. 爬虫分类
根据爬虫的用途和目标网站不同,爬虫可以分为不同种类。常见的爬虫分类如下:
(1)通用爬虫:用于抓取整个互联网上的信息。
(2)聚焦爬虫:用于采集特定网站的信息。
(3)增量式爬虫:对于已经采集过的网站,只抓取新的更新内容。
(4)深度爬虫:用于抓取网站中层数比较深的信息。
3. 爬虫基本流程
爬虫的基本流程包括以下步骤:
(1)确定采集目标网站。
(2)分析网页结构和数据规律,确定采集的方式和方式。
(3)构建爬虫程序,模拟浏览器行为,访问目标网站,并抓取所需数据。
(4)解析抓取到的页面数据,并进行格式化和存储。
二、爬虫实现方法
1. 爬虫工具
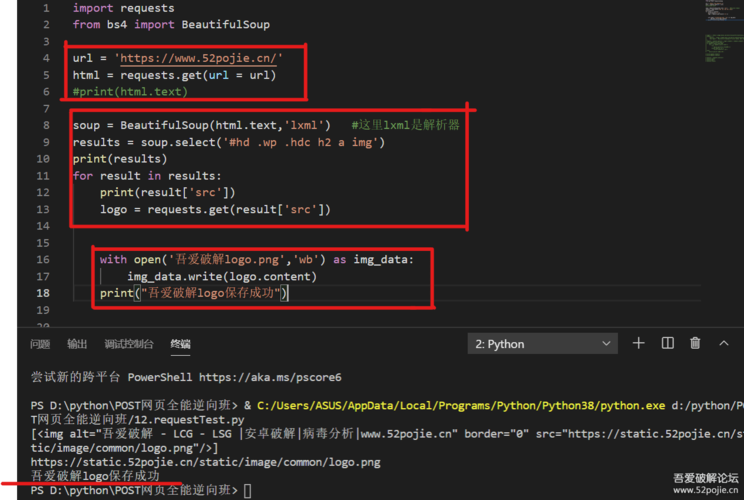
爬虫工具是指一些已经封装好的爬虫程序或脚本,可以直接拿来使用。比较常见的爬虫工具包括Scrapy、BeautifulSoup、urllib2等。
2. 编写爬虫程序
另外一种实现方式是自己编写爬虫程序。一般来说,编写爬虫程序的流程包括以下几步:
(1)确定采集目标网站和所需的数据。
(2)使用爬虫框架或语言(如Scrapy、Python)编写爬虫程序。
(3)选择使用的库和模块,比如requests、beautifulsoup等。
(4)梳理程序结构和逻辑,并进行开发。
三、爬虫实用技巧和注意事项
1. 爬虫的合法性和道德性
在进行爬虫程序开发时,需要遵循一些道德规范和法律规定,比如爬虫要遵守网站的robots.txt协议,避免访问受保护的网站。
2. 爬虫速度设置
在进行爬虫程序开发时,需要合理设置访问速度,比如采用分布式爬虫等技术,避免对目标网站造成过大压力和干扰。
3. 页面解析和数据处理
在进行页面解析和数据处理时,需要注意数据质量和格式化标准,以便后续数据分析和利用。
4. 异常处理和错误监控
编写爬虫程序时,需要考虑各类异常情况,如页面访问失败、连接超时等,以确保程序的稳定性和可靠性。
爬虫技术是网络
版权声明
本文仅代表作者观点,不代表百度立场。
本文系作者授权百度百家发表,未经许可,不得转载。









懿浛
这家伙太懒。。。
- 暂无未发布任何投稿。


