
****
了解Apache Flink编程:流处理框架的工作原理与应用指南
简介:
Apache Flink是一个强大的流处理框架,被广泛用于实时数据处理、事件驱动应用和大规模数据分析。本文将介绍Flink编程的基本概念、工作原理以及在实际应用中的使用指南。
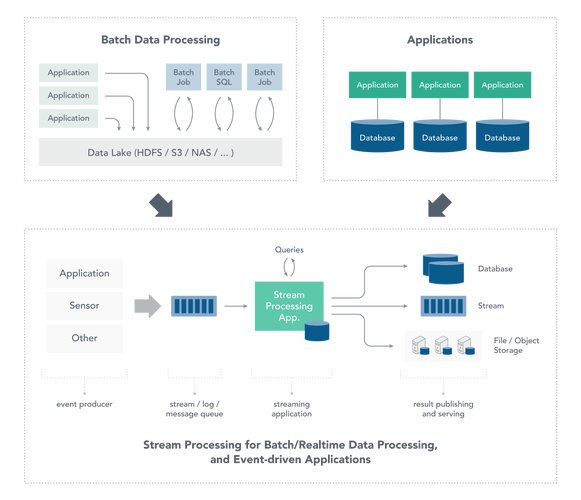
Apache Flink编程简介:
Apache Flink是一个开源的流处理框架,允许开发者高效地处理实时数据流。相比其他流处理框架,Flink具有更强的容错性、更高的吞吐量和更低的延迟,使其成为处理大规模实时数据的理想选择。
Flink提供了丰富的API和库,支持各种流处理和批处理应用。它采用了基于事件时间的处理模型,能够处理乱序事件,并确保精确的结果计算。Flink还提供了灵活的状态管理和容错机制,确保应用程序在故障发生时能够保持稳定运行。
Flink编程的基本概念:
1.
DataStream API:
Flink的DataStream API是其主要的编程接口,用于处理无界数据流。开发者可以通过DataStream API定义数据流的转换、操作和计算逻辑。2.
处理模式:
Flink支持两种主要的处理模式:流处理和批处理。流处理用于处理连续不断的数据流,而批处理则用于处理有限的数据集。3.
窗口操作:
在流处理中,窗口操作是一种常见的数据处理技术,用于将无限的数据流切分成有限的时间窗口,并在每个窗口上进行计算操作。4.
状态管理:
Flink允许开发者在流处理过程中维护和访问状态信息。这对于需要跟踪数据流中的状态或进行复杂的事件处理非常有用。5.
容错机制:
Flink具有强大的容错机制,能够在节点故障或网络分区发生时保持数据一致性和处理正确性。Flink编程的工作原理:
1.
任务调度和执行:
Flink应用程序被编译成有向无环图(DAG),其中每个节点表示一个数据操作。Flink的作业管理器负责将DAG图转换为任务图,并在集群中进行任务调度和执行。2.
状态管理和恢复:
Flink将应用程序状态存储在可插拔的状态后端中,例如内存、文件系统或外部数据库。当发生故障时,Flink能够将状态恢复到先前的一致状态,并继续处理数据流。3.
事件时间处理:
Flink采用基于事件时间的处理模型,确保对乱序事件进行准确处理。Flink使用水位线(Watermark)来衡量事件时间的进展,并根据水位线来触发窗口操作。Flink编程的应用指南:
1.
实时数据处理:
使用Flink可以构建实时的数据处理管道,例如数据清洗、实时计算和实时分析。Flink提供了丰富的转换和算子,使开发者能够轻松地实现复杂的数据处理逻辑。2.
事件驱动应用:
Flink适用于构建事件驱动的应用程序,例如实时监控、异常检测和实时预测。开发者可以利用Flink的状态管理和窗口操作来处理事件流,并实时生成结果。3.
大规模数据分析:
Flink可以处理大规模的数据集,并支持复杂的数据分析任务。开发者可以使用Flink的批处理模式来执行离线数据分析,或者将流处理和批处理结合起来进行混合式的数据处理。结论:
Apache Flink是一个强大而灵活的流处理框架,适用于各种实时数据处理和大规模数据分析场景。通过理解Flink编程的基本概念和工作原理,并遵循相应的应用指南,开发者可以利用Flink构建高效、稳定的流处理应用,并实现复杂的数据处理任务。
版权声明
本文仅代表作者观点,不代表百度立场。
本文系作者授权百度百家发表,未经许可,不得转载。









钦棱
这家伙太懒。。。
- 暂无未发布任何投稿。


